近期,計算機與信息科學學院2021級本科生彭杰在中科院1區Top期刊《Applied Soft Computing》上發表學術論文“Density-based clustering with boundary samples verification”����,陳勇副教授為通訊作者���。

在機器學習領域�����,基于密度的聚類方法是一個重要研究方向。傳統密度聚類技術主要通過分析數據的局部密度來對樣本進行分類。然而�,當處理邊緣區域樣本時����,這些方法面臨著較大挑戰��,如在低密度邊界樣本易被誤判為噪聲,在密度相近且鄰近的兩個群簇之間準確劃分邊界點的困難�����。
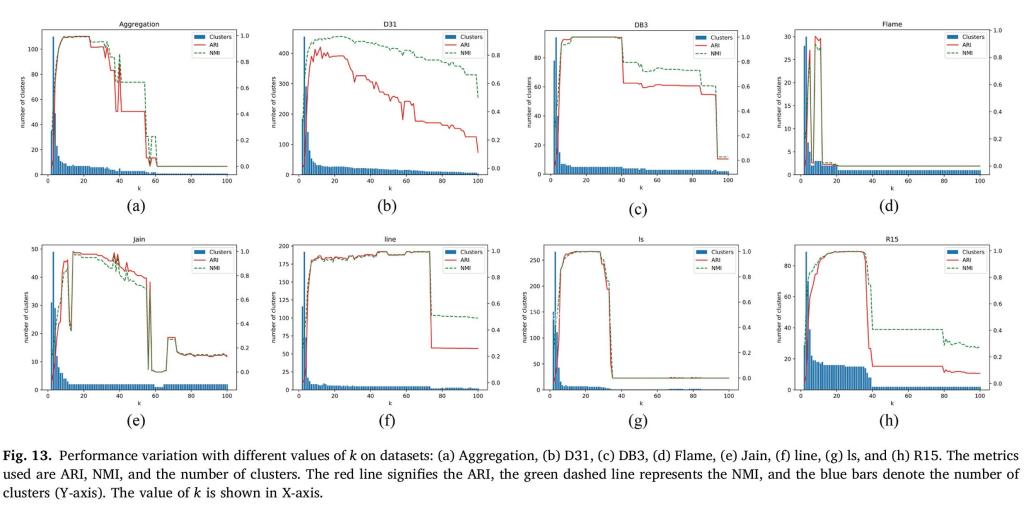
該研究提出了一種基于K最近鄰的密度聚類邊界樣本改進方法,通過深入分析樣本與其K最近鄰的空間關系及其與新形成的簇之間的連接性�,有效識別邊界樣本�����。在所有簇完全形成后,進一步根據樣本的K最近鄰調整其分類標簽���,從而顯著提高對邊界樣本的分類精度。該研究通過在18個公開數據集上進行的廣泛實驗���,驗證了所提出方法的有效性。實驗結果清楚地展示了該方法在處理邊界樣本方面的獨特優勢���,能夠有效提升聚類的準確性和魯棒性。
原文鏈接






